Elasticsearch in Vapor: Getting Started
In this tutorial, you’ll set up a Vapor server to interact with an Elasticsearch server running locally with Docker to store and retrieve recipe documents. By Christian Weinberger.
Elasticsearch is a distributed search and analytics engine for all types of structured and unstructured data. It’s built on Apache Lucene, and is known for its speed and scalability. Elasticsearch provides you with a set of REST APIs to interact with data.
Developers typically use Elasticsearch when they need to deal with a huge amount of data — for example, when storing logs. You’ll use it to index data and make that data available through a powerful search.
In this tutorial, you’ll learn the basics of Elasticsearch, and how to:
- Set it up for the development environment.
- Perform CRUD (Create, Read, Update, Delete) operations.
- Leverage it to search for documents.
You’ll do this by developing a Recipe Finder Web API in Vapor.
Additionally, you should have some experience using Vapor to build web apps. See Getting Started With Server-Side Swift With Vapor if you’re new to Vapor.
Additionally, you should have some experience using Vapor to build web apps. See Getting Started With Server-Side Swift With Vapor if you’re new to Vapor.
Getting Started
Use the Download Materials button at the top or bottom of this page to download the starter project for the Recipe Finder Web API.
Locate starter/recipe-finder-vapor4/ in Finder and double-click Package.swift to open the project in Xcode. Wait while Xcode resolves and fetches the package dependencies — don’t stop the build!
The starter project is a Vapor server that you’ll set up to interact with an Elasticsearch server. You’ll use this setup to store and retrieve recipe documents.
You’ll find an ElasticsearchClient.swift file in Sources/App/Services/Elasticsearch. Now, you just need an Elasticsearch server.
Running Elasticsearch in Docker
To avoid version problems and to isolate Elasticsearch from your system, you’ll run Elasticsearch in a Docker container.
In Terminal, run this command:
docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.6.2
This downloads the Elasticsearch image, if you haven’t downloaded it already, and runs it in a Docker container named elasticsearch. The detach option -d runs the process in the background.
Elasticsearch exposes its API over HTTP on port 9200. The publish option -p 9200:9200 tells Docker to map the container’s internal port 9200 to port 9200 of your host machine.
The environment variable discovery.type starts a single-node Elasticsearch cluster for development or testing, which bypasses bootstrap checks.
Your next step is to verify your Elasticsearch instance is running properly. In a browser window, open http://localhost:9200. You should see something like this:
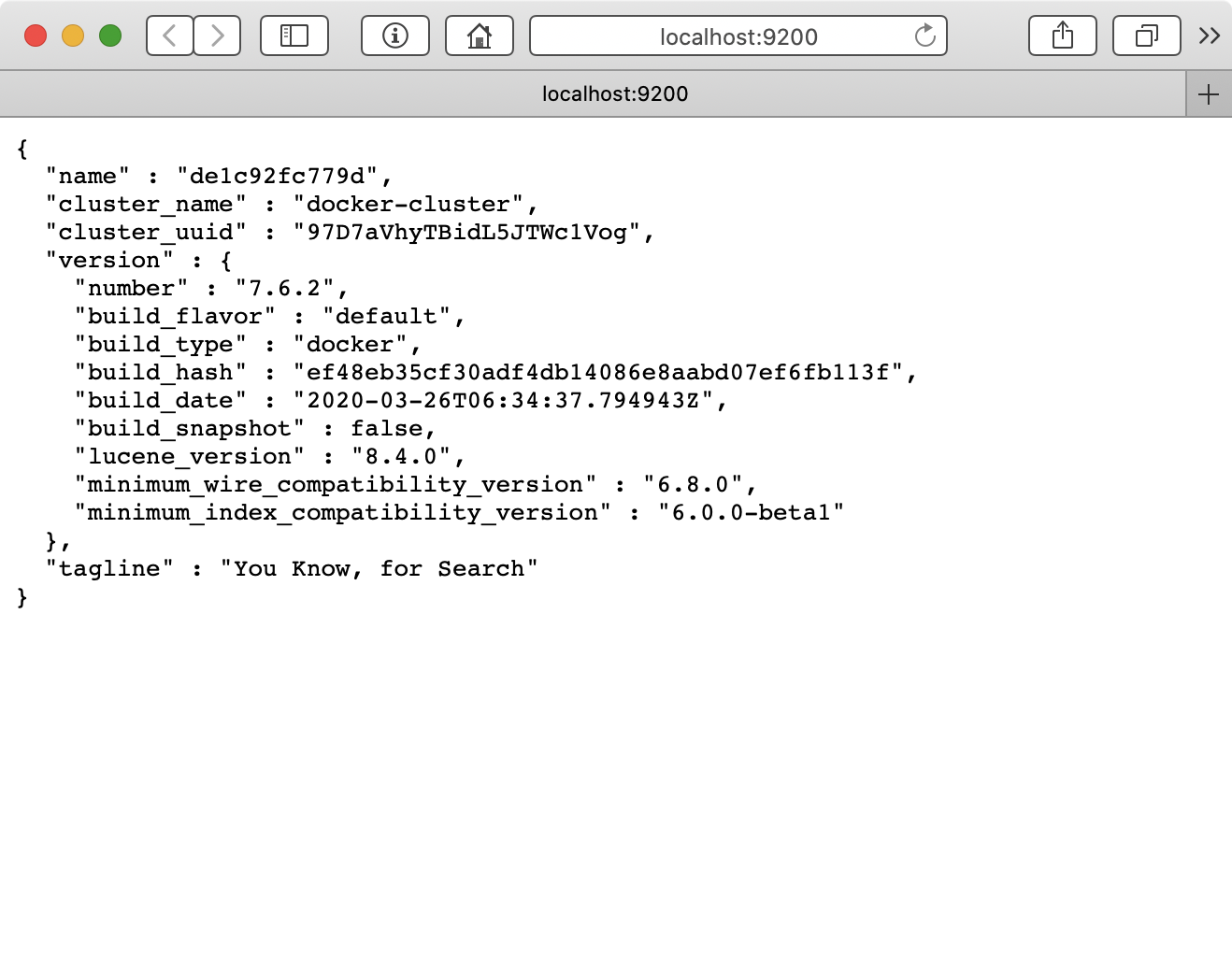
Congrats! You’re now ready to play around with Elasticsearch. You’ll connect your Vapor server to the Elasticsearch server, then implement a REST API for CRUD and search operations on the Vapor server. Requests sent to the Vapor server’s 8080 port will forward to the Elasticsearch server’s 9200 port.
Using Elasticsearch
Elasticsearch is a good choice for relevance-based searching, full-text search, synonym or phonetic search and, if you want to get good search results, even for misspelled search terms. Here’s a look at some of the basics of using Elasticsearch.
Understanding Indexes and Documents
Instead of storing information in rows and columns, Elasticsearch stores JSON documents in indexes. Think of an index as a schematic collection of similar documents, where documents are the basic unit of information you index.
Each index also has one mapping type, which determines how you index the documents. Here’s how you differentiate the two types:
- Dynamic mapping: With this type, which is the default, you don’t have to define fields and mapping types beforehand. Adding a document to the index automatically adds all new fields to the mapping type.
- Explicit mapping: Here, you need to provide the fields and mapping types when you create the index. You can add more fields later.
Explicit mapping has the benefit of giving you control over which fields are relevant for the index and how you preprocess their values. This makes your life easier when doing complex searches. It also has a positive effect on storage and performance.
Comparing Elasticsearch to Relational Databases
Unlike relational databases, Elasticsearch works best without relations. While it’s possible to set some basic relations between documents, those relationships aren’t as powerful as with relational databases like MySQL or PostgreSQL.
In SQL, you try to normalize data as much as possible; the opposite is true in Elasticsearch. You can’t create relations and join indexes to perform queries, so you have to denormalize the data in your indexes. By doing this, you build a powerful cluster that can scale up quickly, as needed.
Implementing CRUD
Now, back to the Xcode project to implement some basic CRUD — Create, Read, Update, Delete — operations so you can store and read recipes from Elasticsearch. To do this, you’ll modify files in Sources/App.
First, you need to specify your model for recipes. Open Models/Recipe.swift and add these properties to Recipe:
var id: String?
var name: String
var description: String
var instructions: String
var ingredients: [String]
This is a very basic model of a recipe, but it’ll do the job. id is Optional since in Elasticsearch, a Recipe only gets an ID after you store it.
Here, ingredients is a simple array of type String. In a more sophisticated version, you’d have a struct with more fields, such as amount and unit.
Next, inspect the classes in Services/Elasticsearch:
Open ElasticsearchClient.swift. It’s already capable of sending requests to a URL and returning a response: EventLoopFuture<Response> or a parsed object: EventLoopFuture<D: Decodable>.
In this file, you’ll only have to worry about the Requests section, where you’ll find method signatures prepared without implementation, except for fatalError() statements, to make the project build.